
发布时间:2025-08-25 来源:奇谱智慧科技
铠侠开发了一种5TB高带宽闪存模块的原型,带宽为64 GB/s,本质上是面向GPU的基于NAND的存储器。与HBM(高带宽存储器)相比,高带宽闪存(HBF)将这一概念应用于NAND闪存,提供DRAM基础HBM的8-16倍容量。通过将速度与持久存储相结合,HBF能够在使用更少功率的情况下高效访问大型AI数据集。

通常,当我们提到“闪存存储”时,首先想到的是容量,其次才是速度。即使是目前最快的PCIe 5.0固态硬盘,例如三星的9100 Pro这类14GB/s级别的驱动器,也远远无法满足现代GPU和CPU的带宽需求。而铠侠的新型原型模块彻底改变了这一现状:它通过PCIe 6.0接口提供5TB的容量和64GB/s的持续带宽,这比目前市场上最快的PCIe 5.0驱动器快4倍以上,并且接近HBM2E每堆栈的吞吐量。
关键在于系统的扩展方式,铠侠没有采用一个中央控制器来管理整个NAND存储库,随着更多芯片和通道的增加,这种方式很容易成为瓶颈。相反,铠侠为每个模块都配备了独立的控制器。这些控制器紧挨着各自的NAND芯片,并以菊花链的方式相互连接。这种设计减少了信号串扰,并消除了随着速度提高而变得越来越难以管理的宽并行总线的复杂性。相反,数据以串行方式传递,每个链路使用PAM4信号以128Gbps的速度传输。
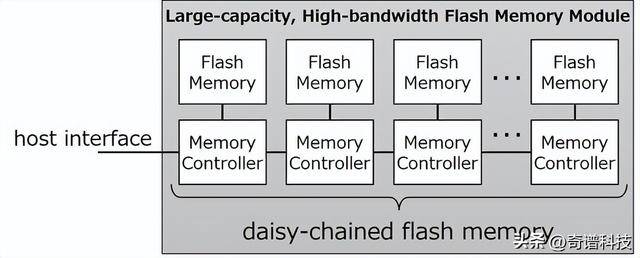
(图片来源:铠侠)
PAM4(四电平脉冲幅度调制)相比传统的 NRZ(不归零)信号,每个符号的数据速率翻倍,但它也更容易受到噪声和比特错误的影响。为了保持信号完整性,Kioxia 依赖于均衡、纠错和更强的预加重措施,这与PCIe 6.0本身的要求类似。
这也从侧面解释了为何要选用PCIe 6.0作为主机接口,因为16通道的PCIe 6.0在理论上能够实现大约128GB/s的双向传输速率。铠侠设定的64GB/s的目标刚好低于该速率上限的一半,这为纠错和额外的开销预留了足够的空间,而不会使总线过载。
(图片来源:铠侠)
正如你可能预期的那样,延迟是主要的权衡因素。HBM内存的工作延迟在几百纳秒的量级,几乎就像GPU寄存器的扩展。即使是带有先进控制器的NAND闪存,其数据访问延迟仍然在几十微秒的量级,这比HBM慢了好几个数量级。铠侠通过积极地预读取和控制器级缓存来应对这一问题,因此顺序工作负载受延迟影响较小。这并不能使NAND的速度达到DRAM的水平,但足以缩小差距,使得在处理流式数据集、AI检查点或大型图分析等场景时,带宽的重要性超过了原始延迟。
功耗是另一个关键因素。铠侠声称每个模块的功耗低于40瓦,这与传统Gen5固态硬盘(对于约14 GB/s的速度,功耗可达15W)相比显得相当出色。从每瓦特每秒吉字节(GB/s per Watt)的效率来看,铠侠的这个模块要高效得多。这非常重要,因为在超大规模数据中心的机架中,几百个存储驱动器很容易就会消耗数千瓦的功率。由于H100集群的使用,AI数据中心功耗预算已经急剧膨胀,在存储层节省每一瓦特的功耗都至关重要。
这些模块也为系统设计带来了新的可能性。由于采用了菊链式连接的控制器,增加更多模块并不会占用额外的带宽,因此性能能够与容量成线性比例地提升。一套完整的16个模块可以达到80TB的闪存容量以及超过1TB/s的吞吐量,在过去,这样的数字只有并行文件系统或者DRAM缓冲区才能达到。这使得存储可以像内存一样被处理,直接位于PCIe互连结构上,与加速器并排,而不是被困在后端 I/O 中。

(图片来源:美光)
这并不是铠侠首次涉足高带宽闪存领域,该公司一直在研究长距离PCIe SSD和GPU对等闪存链路,包括与英伟达共同研究针对1000万IOPS的XL-Flash驱动器。这个原型并非一次性项目,它是一个路线图的暗示,表明NAND不仅会变得更大,而且会变得更快,足够快以靠近计算堆栈。
目前,该模块仍处于原型阶段,围绕它仍有诸多未解之谜:它在处理混合随机工作负载时表现如何,ECC(纠错码)扩展对延迟有何影响,以及在实际的AI训练场景下,其真实吞吐量究竟如何。然而,这里传达的更为关键的信息是,闪存正逐渐摆脱其作为慢速、深层存储的角色,并在存储层级结构中向上攀升。倘若铠侠的愿景得以实现,下一代数据中心或许将见证存储模块与GPU本身一起竞争带宽优势。

